
This past Spring, members of Hive Research Lab worked with students in Indiana University’s IVMOOC, an online information visualization course, to take data about Hive NYC-funded projects and partnerships and see what sorts of interesting patterns might emerge through different visualization techniques. In this two part series, we interview each of the two teams of students that worked with the data to have them share their process, the visualizations they came up with, and reflections on what it was like working with Hive NYC data.
One qualification to note: as the data these visualizations was based on were sometimes incomplete and also self-reported, these should be treated more like prototypes for how we might represent Hive activity, rather than definitive statements of what activity has been.
In this post, we talked with Team EsHkUsNl, made up of Gloria Jimenez, Elwin Koster, Maria Maza, Carmen Ng, Chantal Melser and Kristina Simacek.
Hive Research Lab (HRL): Tell us a bit about your approach to visualizing Hive NYC. What kind of process did the team go through?
Team EsHkUsNl (TE): With an international team spanning the globe, we were challenged to collaborate across different time zones and to learn and draw on each other’s strengths. Using social media, including Google+ hangouts, we were able to facilitate regular collaboration. We were inspired by the fun of doing an online course, and as we progressed in the project it became more of a professional endeavor.
As for the work itself, we approached the project through extensive discussion and sharing of different approaches to visualizations, providing examples from each of our backgrounds and trying to pick out the main elements from each visualization to put together a final visualization that took into account both our desire for a clear and useful visualization as well as balancing the limitations of the data. In analyzing the data, we went through several iterations of visualizations to determine what would best represent the data in a useful way. Each visualization is a multi-layered process, and in the final visualization we attempted to show multiple layers at the same time so that both an overview of the data and specific elements of the data could be shown at once.
We appreciated having the flexibility to come up with what we thought was important to show to key stakeholders, including administrators, donors, organizations, and youth. This allowed us to think freely about what we wanted to show, and experiment with different kinds of data visualizations.
HRL: Let’s have a look at the visualizations that the team produced. What do you think they show about Hive NYC?
TE: Here’s the first visualization we came up with:

Tree Map of the Hive
First, we tried a tree map to highlight how much financial resources were going into different grant categories. This revealed the dollars split down into project and partner organizations. Clearly, the Catalyst grants receive the most money, the Link and Lever grants have less weight in this.
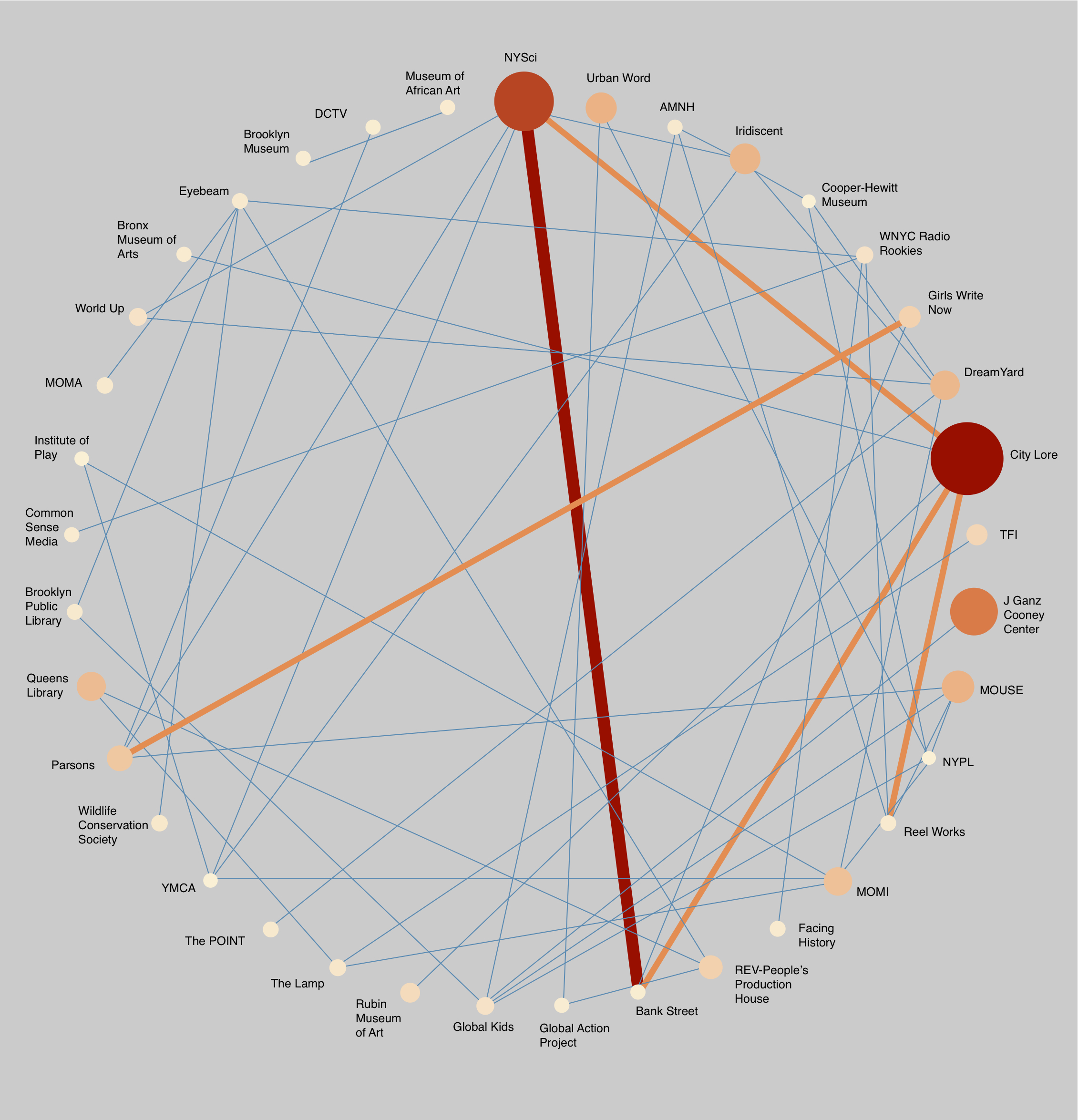
Network Visualization of Hive NYC
Next, we explored a circular network diagram, in order to be able to see the connections between organizations and incorporate the amount of dollars involved by position in the circle. 12-o’clock is highest amount of dollars, then clockwise the amount of dollars decreases. The nodes are sized and colored by the number of youth reached. We realize some of that is sort of skewed though since there were some apples to oranges issues with the youth reached data, as some were counting large online audiences with limited engagement, and others smaller groups with more intensive engagement. We realized that visualizing “impact” in this way can be a little bit of a challenge in terms of telling the story of what’s actually going on in these programs.
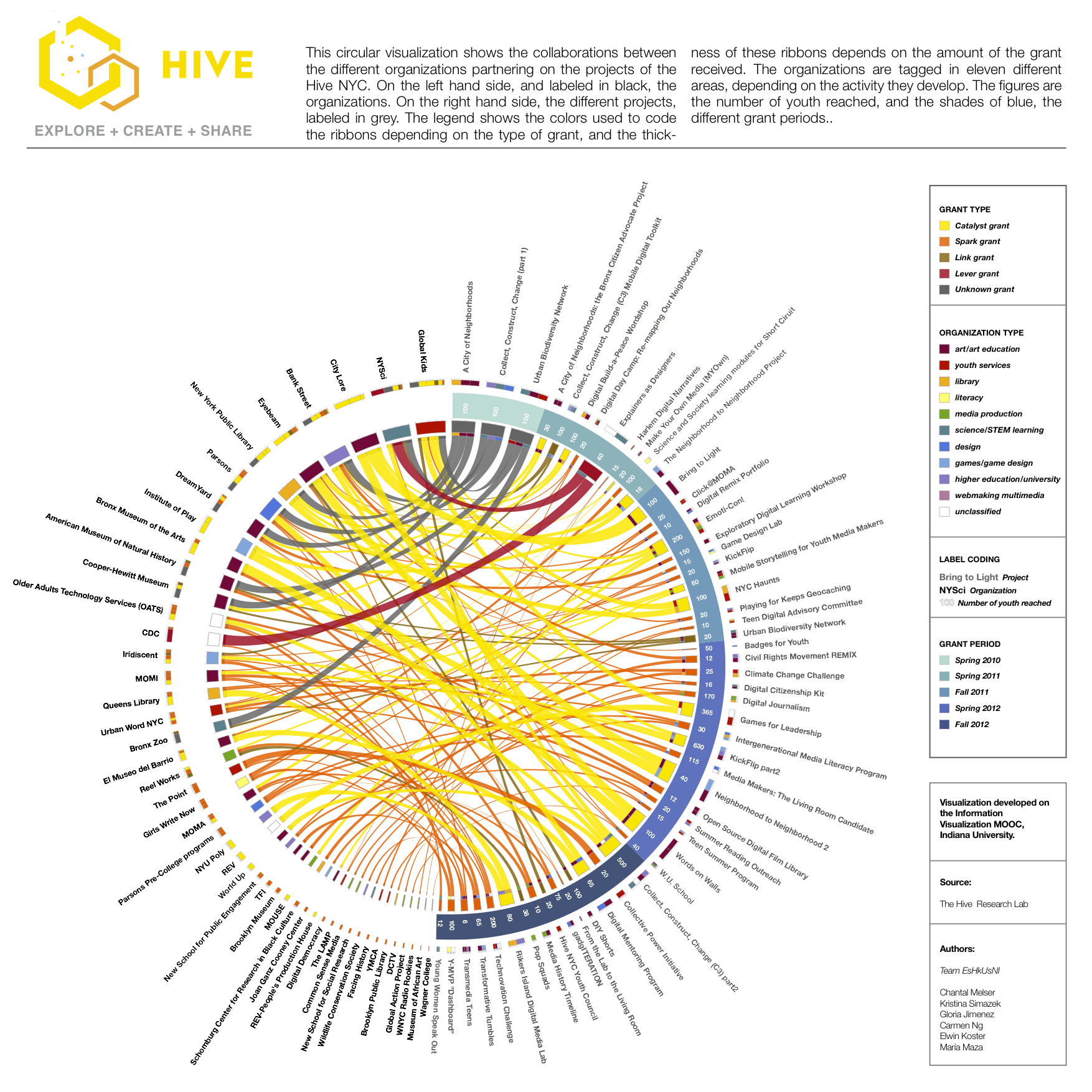
Bipartite Circular Visualization of Hive NYC
For our final visualization, we decided to use a tool called Circos, which places network data in a circular map. With this tool, it is possible to order nodes, select colors for edges, and indicate sizes of edges.
The Circos approach enabled us to place each project in order of season during which the grant was awarded, and to color-code linkages by award type, while sizing linkages by award amount. In cases where multiple groups were involved in the project, the award amount was split among the participating organizations to sum to a total for each project. This approach also minimizes the impact of outliers while allowing for a quick overview of the network with the possibility of zooming in or out to see specific information.
Colors of the “ribbons” in the visualization represent the type of grant awarded to the project. The type of grant is particularly interesting because it delineates the amount of money available and the expected size and scope of the project. Knowing this is important when comparing the relative impact of different projects. For example, a Spark grant is for up to $25,000 to explore a new idea or new direction for one or more organizations, while a Catalyst grant is for two or more organizations to develop a prototype/pilot program at a cost of $25,000 to $100,000.
We think that the visualizations that our team produced show the diversity of projects within Hive NYC. This diversity in themes and types of organizations involved yields potentially wide-reaching impacts to a number of youth. We can see from the visualization the variety of types of projects in which each organization is involved through their participation in Hive NYC.
HRL: Visualization is no easy task. Based on what you all learned through IVMOOC, what would you say are the potentials, but also the limitations, of using data visualization techniques to understand a context like Hive NYC?
TE: A widespread saying goes that an image is worth a thousand words. Yet, it is also easy to lie with images. In showing data within a data visualization one must be aware of what one is showing and how, as well as how it may be interpreted in different cultures. This can make creating a data visualization quite complex. A limitation we ran across, and which would be an issue in any data visualization project is the question of what to show and what to leave out. Particularly as data sets get larger and include more types of information, the question of what parts of the data to highlight and how becomes paramount. In this way the potential to hone in on important themes in the data is great, yet there is always some loss of data in order to keep the data visualization from becoming cluttered and confusing. This makes interactive visualizations particularly useful, as parts of the data set can be highlighted at different times. Yet, interactive visualizations are also limiting because they cannot be used, for example, in print. Furthermore, creating interactive visualizations requires highly specialized skills that may not be available.
Data visualizations can allow for presentation of what might otherwise be dry statistical information into a format that can be interpreted by a wider audience. “The brain doesn’t just process information that comes through the eye. It also creates mental visual images that allow us to reason and plan actions that facilitate survival.” [A.Cairo, The Functional Art (2013), p. xvi]. In this way, and based on this citation we should see the data visualization as a new way to communicate data in a way that fits with the more modern ways of communication.
HRL: You all have largely been doing this work sort of in isolation of actually interacting with folks from Hive NYC, but now you’re getting a chance to talk to the network directly. Any general reflections you’d like to share?
TE: One point we struggled with in visualizing the Hive NYC data was how to show the impact of the projects on youth so that stakeholders can see how effectively their dollars are being used. This must be understood also in the context of the types of grants offered by the Hive Digital Media Learning Fund, as some are intended to fund pilot projects, while others aim to substantially expand existing or previously piloted projects. In this way, data visualization can be used as an instrument to inform potential donors as to how their donation can make a difference in the lives of youth.
As a team working on a graphical representation of data we have clearly learned the value of such kind of visualizations in modern society, and we definitely believe it might be valuable for the Hive NYC to provide more opportunity think understand and create visualizations. Not only for the youth, and also for the organizations involved.
HRL: As some of you might know, part of our mandate at Hive Research Lab is to show how data and research can be used to advance the practice of Hive as well as communicate its activity to broad stakeholders. How do you think the work you all have done here helps to build a case for the utility of research for practitioners?
TE: We believe, as we said in our answer above, that using this way of visualizations as an instrument to inform both the stakeholders and the participants is a very powerful tool. Making the right combinations in your visualizations, in addition to displaying direct impact of funding on projects and youth, may show unexpected links that can trigger both the organizations as well as the funders to think of new projects and new directions. Visualizations are a useful way to make a strong case for the success and challenges of implementing programs such as those in Hive NYC.
HRL: Thanks so much for sharing your perspectives, and for providing some new ways of making the activity of Hive NYC visible!
TE: You’re very welcome!

Pingback: Visualizing Hive NYC – Part 2 |
Pingback: Google Earth Data Visualization: Eye-Popping Videos | The Source For NAR Commercial Real Estate